前言:记录使用Python中一些有意思的事情.
Python读取.data数据占用的内存
2018/4/19记录
昨天是腾讯广告算法大赛第一天,本咸鱼本着试水的心态下载了数据集,数据大小如下: 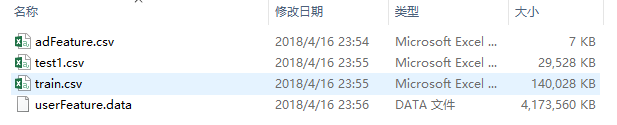 其中最大的文件userFeature.data有4075MB,用Sublime Text3打开,发现其占用了7914MB大小的内存,这和2倍大小的内存原则完全一致:
其中最大的文件userFeature.data有4075MB,用Sublime Text3打开,发现其占用了7914MB大小的内存,这和2倍大小的内存原则完全一致: 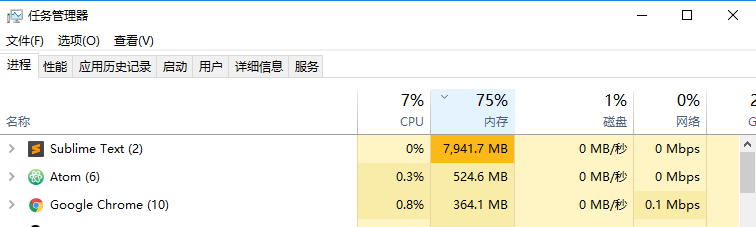 尝试执行以下Python代码读取该.data文件,代码参考了这个baseline:
尝试执行以下Python代码读取该.data文件,代码参考了这个baseline: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46import pandas as pd
import time
import os
import gc
def getdata():
time1 = time.time()
homedir = os.getcwd()
adFeature = pd.read_csv(homedir + '\\data\\adFeature.csv') #7KB
test1 = pd.read_csv(homedir + '\\data\\test1.csv')# 29MB
train = pd.read_csv(homedir + '\\data\\train.csv') # 140MB
if os.path.exists(homedir + '\\data\\userFeature_csv\\userFeature_11.csv'):
userFeature = pd.read_csv(homedir + '\\data\\userFeature_csv\\userFeature_0.csv')
print("read one million")
for i in range(11):
userFeature = userFeature.append(pd.read_csv(homedir + '\\data\\userFeature_csv\\userFeature_' + str(i+1) + '.csv'))
print("read one million")
else:
userFeature_list = []
userFeature = []
with open(homedir + '\\data\\userFeature.data', 'r') as f: # 4173MB
for i, line in enumerate(f):
line = line.strip().split('|')
userFeature_dict = {}
for each in line:
each_list = each.split(' ')
userFeature_dict[each_list[0]] = ' '.join(each_list[1:])
userFeature_list.append(userFeature_dict)
if i % 100000 == 0:
print(i)
for i in range(11):
userFeature_temp = pd.DataFrame(userFeature_list[i*1000000:(i+1)*1000000])
userFeature_temp.to_csv(homedir + '\\data\\userFeature_csv\\userFeature_' + str(i) + '.csv', index=False)
print("save one million")
del userFeature_temp
gc.collect()
userFeature_temp = pd.DataFrame(userFeature_list[11000000:])
userFeature_temp.to_csv(homedir + '\\data\\userFeature_csv\\userFeature_11.csv', index=False)
print("save as csv successfully")
del userFeature_temp
gc.collect()
time2 = time.time()
print("get data cost",time2 - time1,"s")
return adFeature, test1, train, userFeature
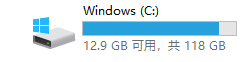
adFeature, test1, train, userFeature = getdata()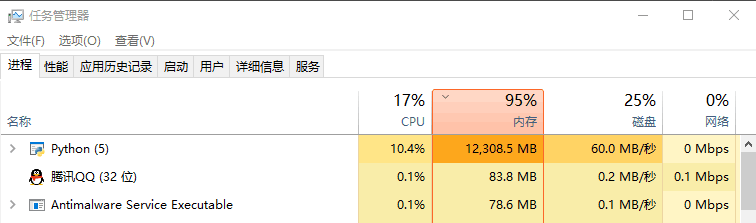 外加征用了固态盘C的13.3G的容量,(征用前剩26.2G,征用后剩12.9G):
外加征用了固态盘C的13.3G的容量,(征用前剩26.2G,征用后剩12.9G): 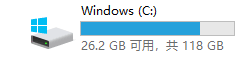
 所以4G大小的数据用Python导入一共会产生25.3G的内存占用.(Why? :) ) 执行以下代码会返回此时局部变量占用空间大小:
所以4G大小的数据用Python导入一共会产生25.3G的内存占用.(Why? :) ) 执行以下代码会返回此时局部变量占用空间大小:
1 | locals().keys() |
发现占用最大的就是userFeature_list,大概10.9G的样子.(So why 25.3G? :) )此时若是把想把userFeature_list转为DataFrame型数据则会抛出MemoryError,故只能分批次转DataFrame并保存为csv,最后在执行一遍会把csv文件读入:
1 | for i in range(11): |
第一次执行结果图如下: 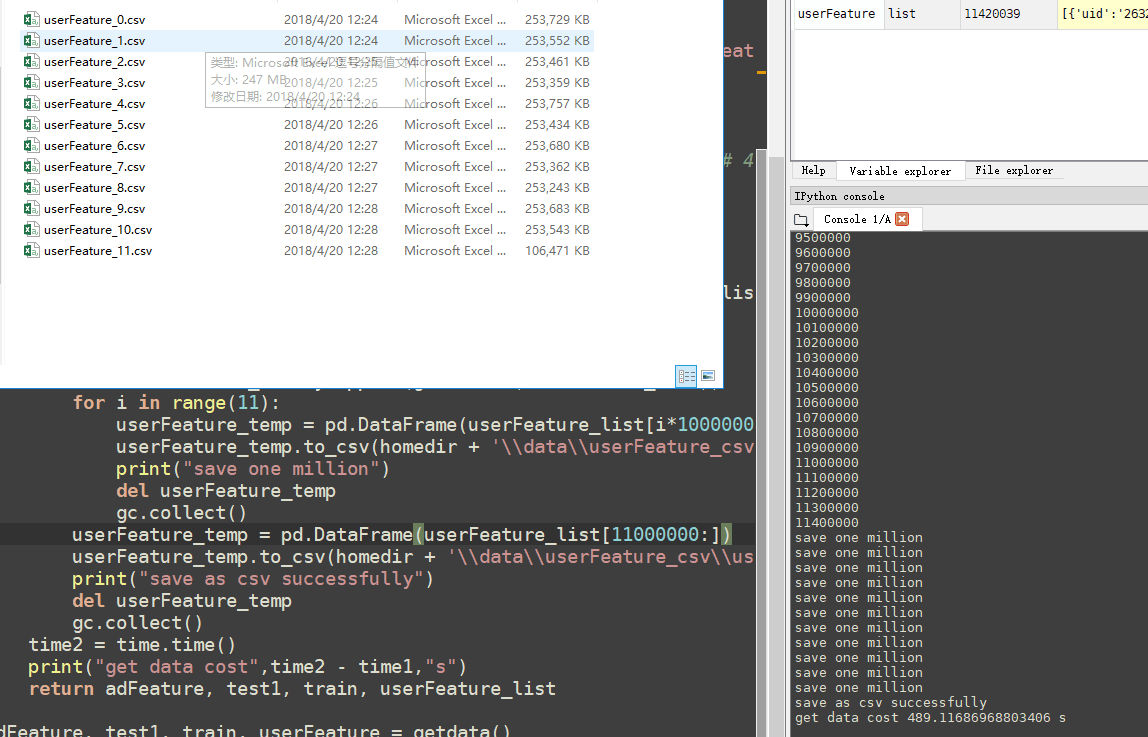 第二次执行因为已经有了csv文件,所以直接读入csv就好,执行结果图如下:
第二次执行因为已经有了csv文件,所以直接读入csv就好,执行结果图如下: 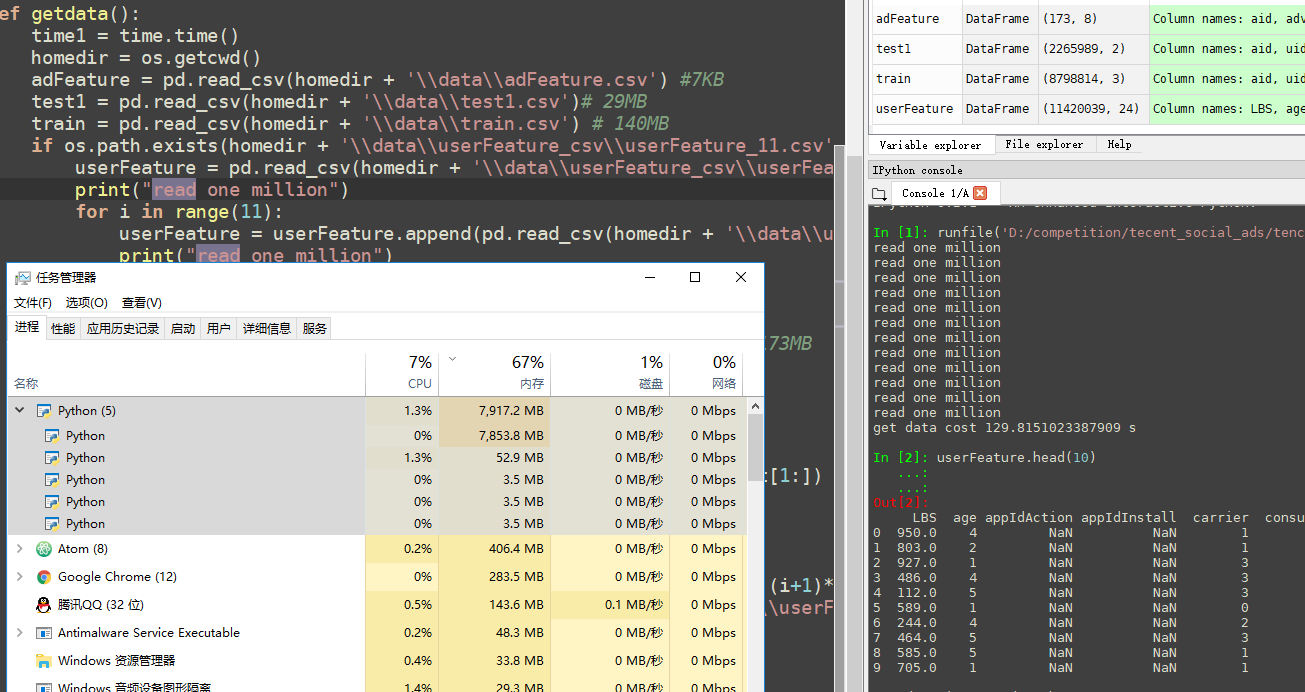
2018/5/25记录
此时初赛已经结束了,最好成绩为0.745764,没能进复赛. 初赛阶段都结束时才发现一种流式逐行读取数据,填充缺失数据为-1,逐行保存为csv文件的方法,特此补充:
1 | import pandas as pd |