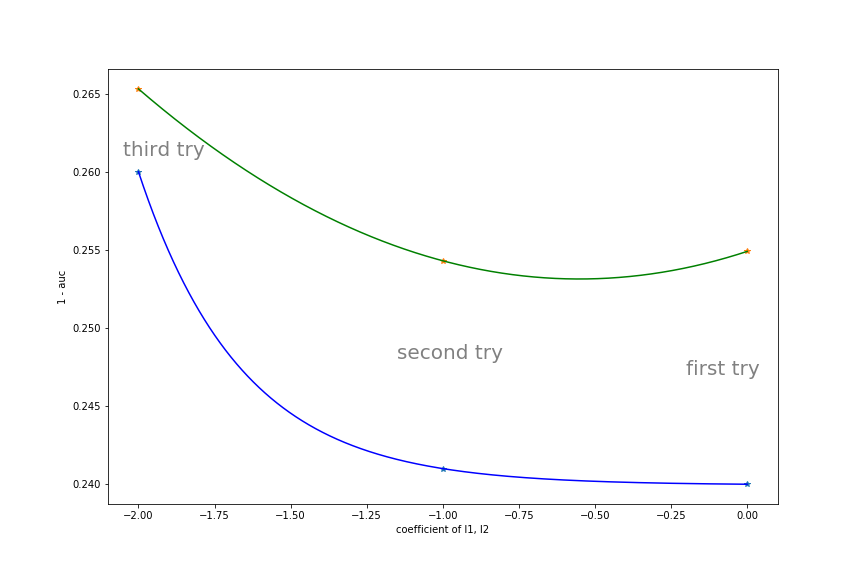
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
| import pandas as pd
import lightgbm as lgb
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.preprocessing import OneHotEncoder,LabelEncoder
from scipy import sparse
import os
import gc
import math
import numpy as np
from sklearn.model_selection import train_test_split
from matplotlib import pyplot as plt
homedir = os.getcwd()
def getdata():
print("read data")
adFeature = pd.read_csv(homedir + '\\data\\adFeature.csv')
test1 = pd.read_csv(homedir + '\\data\\test2.csv')
train = pd.read_csv(homedir + '\\data\\train.csv')
if os.path.exists(homedir + '\\data\\userFeature_csv\\userFeature_11.csv'):
userFeature = pd.read_csv(homedir + '\\data\\userFeature_csv\\userFeature_0.csv')
print("read one million")
for i in range(11):
userFeature = userFeature.append(pd.read_csv(homedir + '\\data\\userFeature_csv\\userFeature_' + str(i+1) + '.csv'))
print("read one million")
else:
userFeature_list = []
userFeature = []
with open(homedir + '\\data\\userFeature.data', 'r') as f:
for i, line in enumerate(f):
line = line.strip().split('|')
userFeature_dict = {}
for each in line:
each_list = each.split(' ')
userFeature_dict[each_list[0]] = ' '.join(each_list[1:])
userFeature_list.append(userFeature_dict)
if i % 100000 == 0:
print(i)
for i in range(11):
userFeature_temp = pd.DataFrame(userFeature_list[i*1000000:(i+1)*1000000])
userFeature_temp.to_csv(homedir + '\\data\\userFeature_csv\\userFeature_' + str(i) + '.csv', index=False)
print("save one million")
del userFeature_temp
gc.collect()
userFeature_temp = pd.DataFrame(userFeature_list[11000000:])
userFeature_temp.to_csv(homedir + '\\data\\userFeature_csv\\userFeature_11.csv', index=False)
print("save as csv successfully")
del userFeature_temp
gc.collect()
return mergedata(adFeature, test1, train, userFeature)
def mergedata(adFeature, test1, train, userFeature):
print("merge data and set na as -1")
train.loc[train['label']==-1, 'label'] = 0
test1['label'] = -1
data = pd.concat([train, test1])
data = pd.merge(data, adFeature, on='aid', how='left')
data = pd.merge(data, userFeature, on='uid', how='left')
data = data.fillna('-1')
return data
def batch_predict(data,index):
one_hot_feature=['LBS','age','carrier','consumptionAbility','education','gender','house','os','ct','marriageStatus','advertiserId','campaignId', 'creativeId',
'adCategoryId', 'productId', 'productType']
vector_feature=['appIdAction','appIdInstall','interest1','interest2','interest3','interest4','interest5','kw1','kw2','kw3','topic1','topic2','topic3']
for feature in one_hot_feature:
try:
data[feature] = LabelEncoder().fit_transform(data[feature].apply(int))
except:
data[feature] = LabelEncoder().fit_transform(data[feature])
train=data[data.label!=-1]
train_y=train.pop('label')
test=data[data.label==-1]
res=test[['aid','uid']]
test=test.drop('label',axis=1)
enc = OneHotEncoder()
train_x=train[['creativeSize']]
test_x=test[['creativeSize']]
for feature in one_hot_feature:
enc.fit(data[feature].values.reshape(-1, 1))
del data[feature]
gc.collect()
train_a = enc.transform(train[feature].values.reshape(-1, 1))
test_a = enc.transform(test[feature].values.reshape(-1, 1))
train_x = sparse.hstack((train_x, train_a))
test_x = sparse.hstack((test_x, test_a))
print(feature+' finish')
cv=CountVectorizer()
for feature in vector_feature:
cv.fit(data[feature])
del data[feature]
gc.collect()
train_a = cv.transform(train[feature])
test_a = cv.transform(test[feature])
train_x = sparse.hstack((train_x, train_a))
test_x = sparse.hstack((test_x, test_a))
print(feature + ' finish')
del data
gc.collect()
return LGB_predict(train_x, train_y, test_x, res, index)
def LGB_predict(train_x, train_y, test_x, res, index):
print("split train data as train and eval")
train_x, evals_x, train_y, evals_y = train_test_split(train_x, train_y,test_size=0.2)
gc.collect()
clf = lgb.LGBMClassifier(
boosting_type='gbdt', num_leaves=127, reg_alpha=10, reg_lambda=10,
max_depth=8, n_estimators=10000, objective='binary', metric= 'binary_logloss',
subsample=0.7, colsample_bytree=0.7, subsample_freq=1,
learning_rate=0.05, min_child_weight=20, random_state=2018, n_jobs=-1
)
clf.fit(train_x, train_y, eval_set=[(evals_x, evals_y)], eval_metric='auc',early_stopping_rounds=200)
print("predict")
res['score'+str(index)] = clf.predict_proba(test_x)[:,1]
res['score'+str(index)] = res['score'+str(index)].apply(lambda x: float('%.6f' % x))
auc_valid = clf.evals_result_['valid_0']['auc']
print("save valid auc curve")
plt.figure(figsize=(60, 40))
plt.plot(auc_valid)
plt.title(max(clf.evals_result_['valid_0']['auc']))
plt.savefig('./picture/'+ str(i) + '.png')
plt.show()
gc.collect()
res=res.reset_index(drop=True)
return res['score'+str(index)]
data=getdata()
train=data[data['label']!=-1]
test=data[data['label']==-1]
del data
gc.collect()
predict=pd.read_csv('./data/test2.csv')
print("分片")
cnt = 1
size = math.ceil(len(train) / cnt)
result=[]
for i in range(cnt):
start = size * i
end = (i + 1) * size if (i + 1) * size < len(train) else len(train)
slice = train[start:end]
result.append(batch_predict(pd.concat([slice,test]),i))
print(str(i),'/',str(cnt))
gc.collect()
result=pd.concat(result,axis=1)
result['score']=np.mean(result,axis=1)
result['score'] = result['score'].apply(lambda x: float('%.6f' % x))
result=result.reset_index(drop=True)
print("save as csv")
result=pd.concat([predict[['aid','uid']].reset_index(drop=True),result['score']],axis=1)
result[['aid','uid','score']].to_csv('./submission.csv', index=False)
|