本文总结了笔者在机器学习中碰到的各种Trade-Off
模型复杂度的Trade-Off
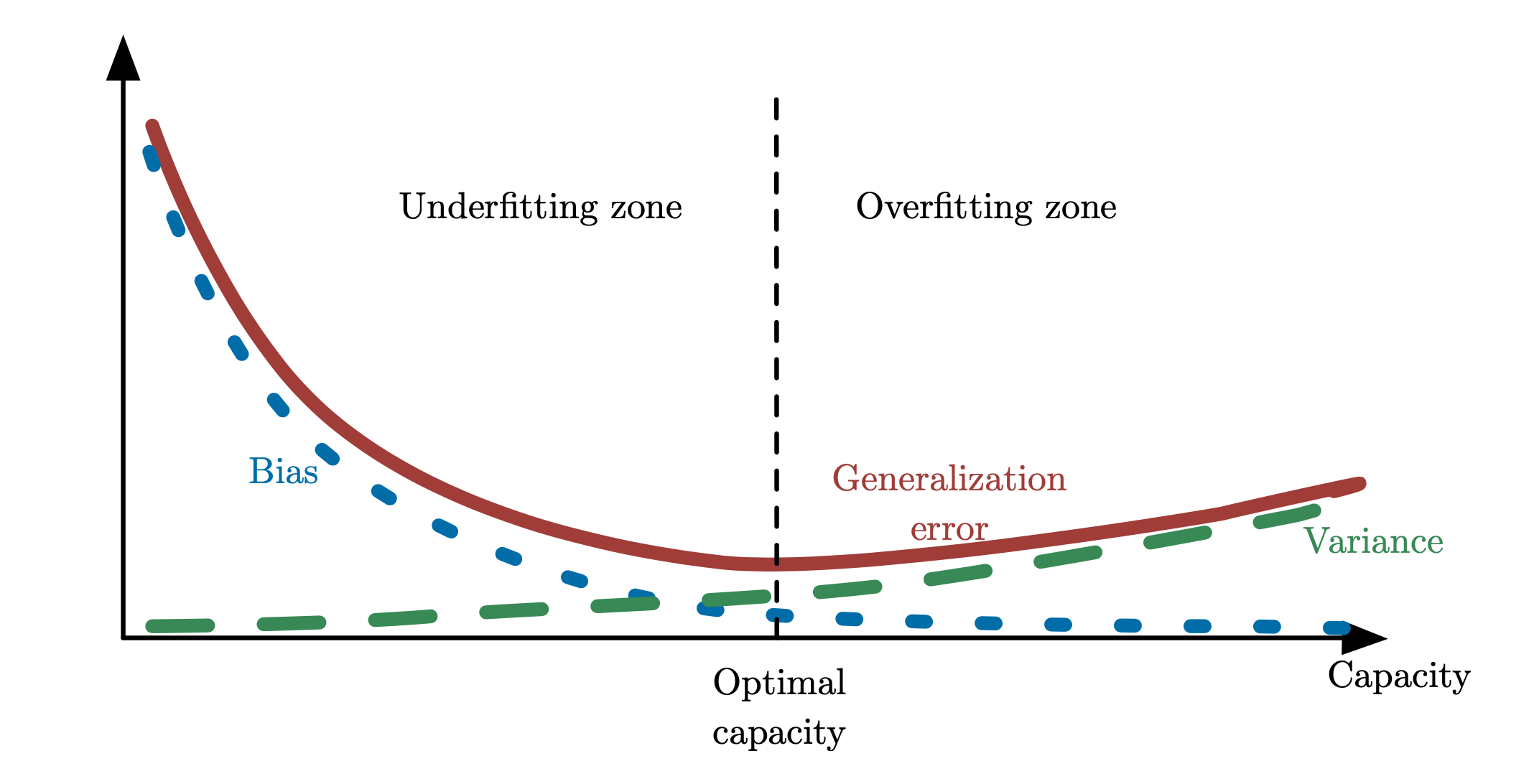
- 在训练集给定的场景(预定给定一个较大的训练数据集应该是最常见的), 模型的复杂度(capacity)要适中选择. (p.s.具体到二分类问题, 最常见模型的复杂度为拉德马赫复杂度Rademacher complexity, 虽然已经有一些依赖于训练集&复杂度的数据相关界去约束住泛化误差(Generalization error), 但仍然缺少更一般的、更容易计算的模型复杂度。)
- 过大的模型的复杂度, 容易使得训练好的模型在训练集上过拟合, 对应high bias & low Variance的情况.
- 过大的模型的复杂度, 容易使得训练好的模型在训练集上欠拟合, 对应low bias & high Variance的情况.
验证集大小的Trade-Off
- 为了衡量泛化误差, 最常见的做法是取一个与训练集同分布、相对较小的数据比例(从以前的20%到现在的1%) 作为验证集, 来粗略的评估泛化误差, 从而根据泛化误差的最小值来给出结束训练的建议.
- 过大的验证集带来可用训练集的缩小与额外计算量的增大.
- 过小的验证集容易使得验证集损失的波动, 从而降低了结束训练建议的可靠度.
损失函数的Trade-Off
- 损失函数的往往在人们用的最多的那几个loss中选取, 但未必是那个ground truth.(p.s. 以语音领域的信号处理为例, 信号处理会服务于下游的唤醒识别, 因此信号处理的AI模型的真正目标往往是唤醒识别率)
- 损失函数的选取越靠近ground truth, 往往越难以去执行最优化算法. (p.s. 直接选择唤醒识别率作为损失函数必然是难以优化)
- 损失函数的选取越远离ground truth, 训练之后模型越不容易达到我们想要的模型效果. (p.s. 选择语音领域更为流行的sisnr、mse损失, 会使得最优化算法容易执行, 但唤醒识别的最好的模型需要通过手动测唤醒识别挑选得到)